
The journey of implementing the WinZigC programming language
Published on February 05, 2024
When I was an undergraduate, I took the Compiler Design module during the last semester of my final year. It was an engaging module that allowed us to see how the knowledge gained from other core Computer Science modules, such as Data Structures and Algorithms, and Theory of Computing, could be applied together. As the semester project for the module, we were given a grammar for a programming language called WinZigC and were tasked with writing a parser to construct the Abstract Syntax Tree (AST) for a given set of test programs.
I successfully completed the assignment by writing both a top-down parser and a bottom-up parser (utilizing a left-child right-sibling binary tree). The latter method was the preferred approach for the assignment. Additionally, we delved into the application of attribute grammar to generate code for a stack machine in a language called Tiny. This task proved to be time-consuming even for a simple program, and, of course, there was an exam question related to it.
WinZigC compiler
Fast forward to December 2023. When I look back at those test programs for the WinZigC grammar, they turn out to be valid programs, and I can interpret the results in my mind. I thought, why not write a compiler for the WinZigC grammar and see how it runs on real hardware? During my search, I stumbled upon a project called LLVM, which provides the infrastructure for writing compilers. This project has had a significant impact on the tech industry, powering AI and large language models (LLMs). For instance, when you train a model using Python libraries on a TPU (Tensor Processing Unit), LLVM plays a crucial role in making this process possible. Moreover, languages like C++, Swift, Rust, and many others use LLVM as their backend.
Exploring LLVM
The most amazing concept in LLVM is the existence of a language-agnostic form used to describe a program called the Intermediate Representation (IR). IR sits between high-level programming languages and machine code. It shares similarities with assembly, but it is not purely assembly. When you have a program in the IR, you can perform analyses and optimizations at that level and then compile it to the machine architecture of your choice. This process makes building compilers incredibly flexible and helps avoid repetitive work across compiler implementations.
I went through the tutorial for implementing Kaleidoscope. The primary goal of this tutorial is to provide ideas about LLVM constructs when implementing a language. I gained insights into concepts such as SSA form, where you generate instructions for a machine with an infinite number of registers, each of which can be assigned only once. While following the tutorial, I began considering ways to bring the WinZigC grammar to generate LLVM bitcode.
Observations from the WinZigC test programs
In some programs, I noticed instances of assigning to an undeclared variable 'd'. Initially, I thought these were syntactically correct but semantically incorrect programs. However, upon looking into the grammar and examining a few programs, I realized that these programs are indeed correct. The undeclared variable is mysteriously declared, and its purpose is to discard the return value of a function call when it is not used. Of course, there isn't a void return type in the grammar.
Another observation I made was the presence of assignments to the function name within the function. I understood that this is a mechanism to change the return value of the function without explicitly using a return statement. This feature, although unconventional in some programming languages, is known and used in languages like PASCAL.
Choices I made for the project
I implemented the compiler using C++ since LLVM is also written in C++, making it easy to add LLVM libraries as dependencies. I chose Bazel as the build system and utilized Google-published Bazel build libraries for LLVM (LLVM upstream uses CMake as its build system). For logging, I integrated glog, and for writing tests, I employed googletest. All of these projects are amazing open-source initiatives from Google.
In my codebase, I added only the dependencies required for generating LLVM bitcode. Consequently, the clang backend is utilized to build the binary for machine code. Clang supports cross-compilation and defaults to the host machine architecture; in my case, it compiled to x86-64 architecture for my Intel Macbook.
First things first
I started by writing a few lines of code and configured the LLDB Debugger for Visual Studio Code. This setup significantly sped up my debugging process and proved invaluable in addressing runtime issues. Additionally, I developed a simple bash script for compiling and running programs, a process that continued to evolve with the incorporation of unit and integration tests.
For testing, each program included numerous language constructs. This allowed me to iteratively test individual programs as I implemented more features. The first functionality I implemented was simple expression evaluation and printing. To handle input and output, I utilized the C library functions scanf and printf. At this stage, the program could read input from the command line and output results accordingly.
Subsequently, I proceeded to implement binary expressions and control flows (branching and looping).
WinZigC program -> executable binary
The process a WinZigC program goes through to become an executable binary is as follows:
- A WinZigC program is just a text file. The Lexer identifies different tokens such as integers, identifiers, operators (+ * := and mod), delimeters (begin, end), comments, spaces, and newlines. The latter three are ingnored by the Screener.
- Labeled tokens are then fed into the Parser. The Parser constructs the Abstract Syntax Tree (AST) using Look-Ahead Top-Down derivation.
- Next, the AST nodes are visited using the visitor pattern in a depth-first manner to generate instructions. An LLVM BasicBlock is created to group a sequence of instructions with a label. When branching occurs, a branch instruction is added to navigate to the destination BasicBlock.
- At this point, we have LLVM bitcode (IR) created in memory. Optional optimizations can be applied to this bitcode. It can then be serialized into binary or human-readable text form.
- In the final step, the Clang backend creates a binary with the target machine architecture using above bitcode.
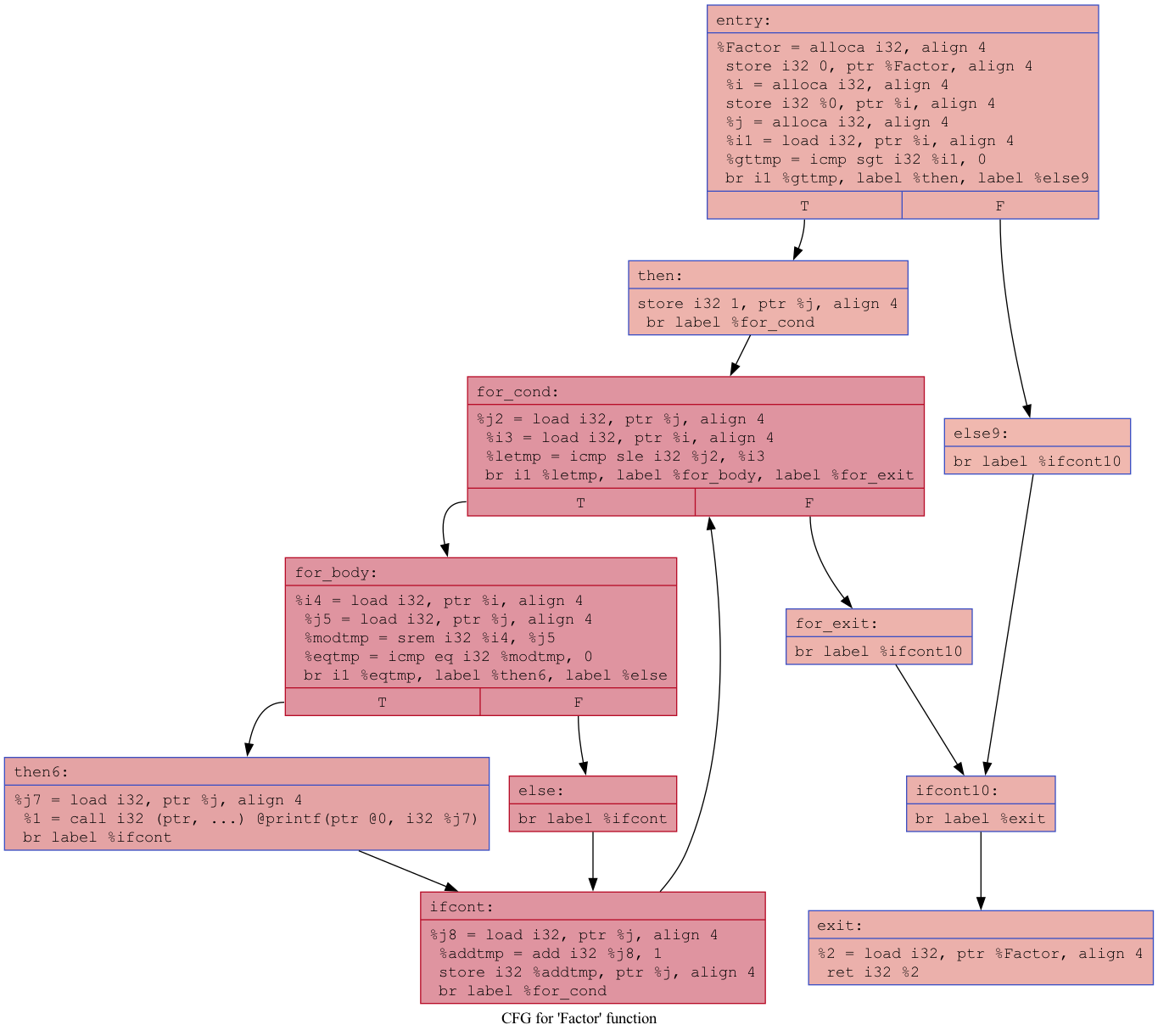
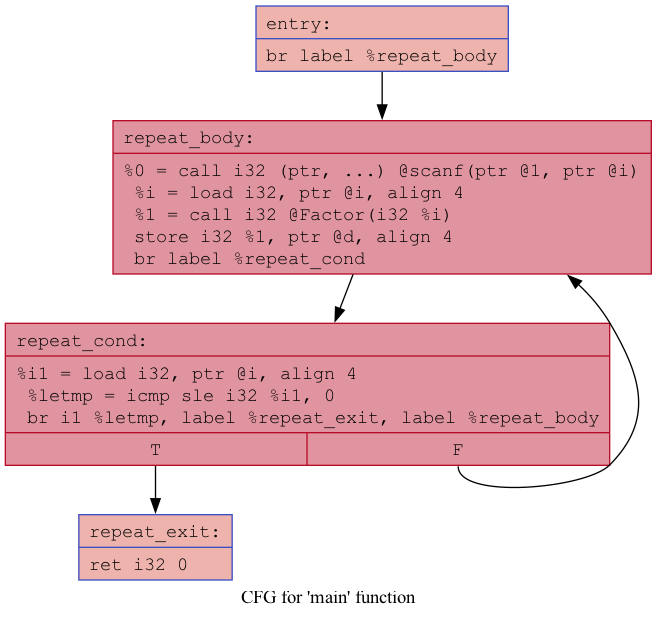
Below is a sample WinZigC program and the LLVM text representation and the Control flow graph (CFG):
A WinZigC program to find factors of an integer
program factors:
var
i : integer;
function Factor ( i : integer ):integer;
var
j : integer;
begin
if i > 0 then
for (j := 1; j <= i; j:=j+1)
if i mod j = 0 then output ( j )
end Factor;
begin
repeat
read(i);
d:=Factor ( i )
until i <= 0
end factors.LLVM bitcode for the 'factors' program before optimizations
; ModuleID = 'factors'
source_filename = "factors"
@d = internal global i32 0
@i = internal global i32 0
@0 = private unnamed_addr constant [4 x i8] c"%d\0A\00", align 1
@1 = private unnamed_addr constant [3 x i8] c"%d\00", align 1
declare i32 @printf(i8*, ...)
declare i32 @scanf(i8*, ...)
define i32 @Factor(i32 %0) {
entry:
%Factor = alloca i32, align 4
store i32 0, i32* %Factor, align 4
%i = alloca i32, align 4
store i32 %0, i32* %i, align 4
%j = alloca i32, align 4
%i1 = load i32, i32* %i, align 4
%gttmp = icmp sgt i32 %i1, 0
br i1 %gttmp, label %then, label %else9
then: ; preds = %entry
store i32 1, i32* %j, align 4
br label %for_cond
for_cond: ; preds = %ifcont, %then
%j2 = load i32, i32* %j, align 4
%i3 = load i32, i32* %i, align 4
%letmp = icmp sle i32 %j2, %i3
br i1 %letmp, label %for_body, label %for_exit
for_body: ; preds = %for_cond
%i4 = load i32, i32* %i, align 4
%j5 = load i32, i32* %j, align 4
%modtmp = srem i32 %i4, %j5
%eqtmp = icmp eq i32 %modtmp, 0
br i1 %eqtmp, label %then6, label %else
then6: ; preds = %for_body
%j7 = load i32, i32* %j, align 4
%1 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @0, i32 0, i32 0), i32 %j7)
br label %ifcont
else: ; preds = %for_body
br label %ifcont
ifcont: ; preds = %else, %then6
%j8 = load i32, i32* %j, align 4
%addtmp = add i32 %j8, 1
store i32 %addtmp, i32* %j, align 4
br label %for_cond
for_exit: ; preds = %for_cond
br label %ifcont10
else9: ; preds = %entry
br label %ifcont10
ifcont10: ; preds = %else9, %for_exit
br label %exit
exit: ; preds = %ifcont10
%2 = load i32, i32* %Factor, align 4
ret i32 %2
}
define i32 @main() {
entry:
br label %repeat_body
repeat_body: ; preds = %repeat_cond, %entry
%0 = call i32 (i8*, ...) @scanf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @1, i32 0, i32 0), i32* @i)
%i = load i32, i32* @i, align 4
%1 = call i32 @Factor(i32 %i)
store i32 %1, i32* @d, align 4
br label %repeat_cond
repeat_cond: ; preds = %repeat_body
%i1 = load i32, i32* @i, align 4
%letmp = icmp sle i32 % i1, 0
br i1 %letmp, label %repeat_exit, label %repeat_body
repeat_exit: ; preds = %repeat_cond
ret i32 0
}CFGs for the 'factors' program before optimizations
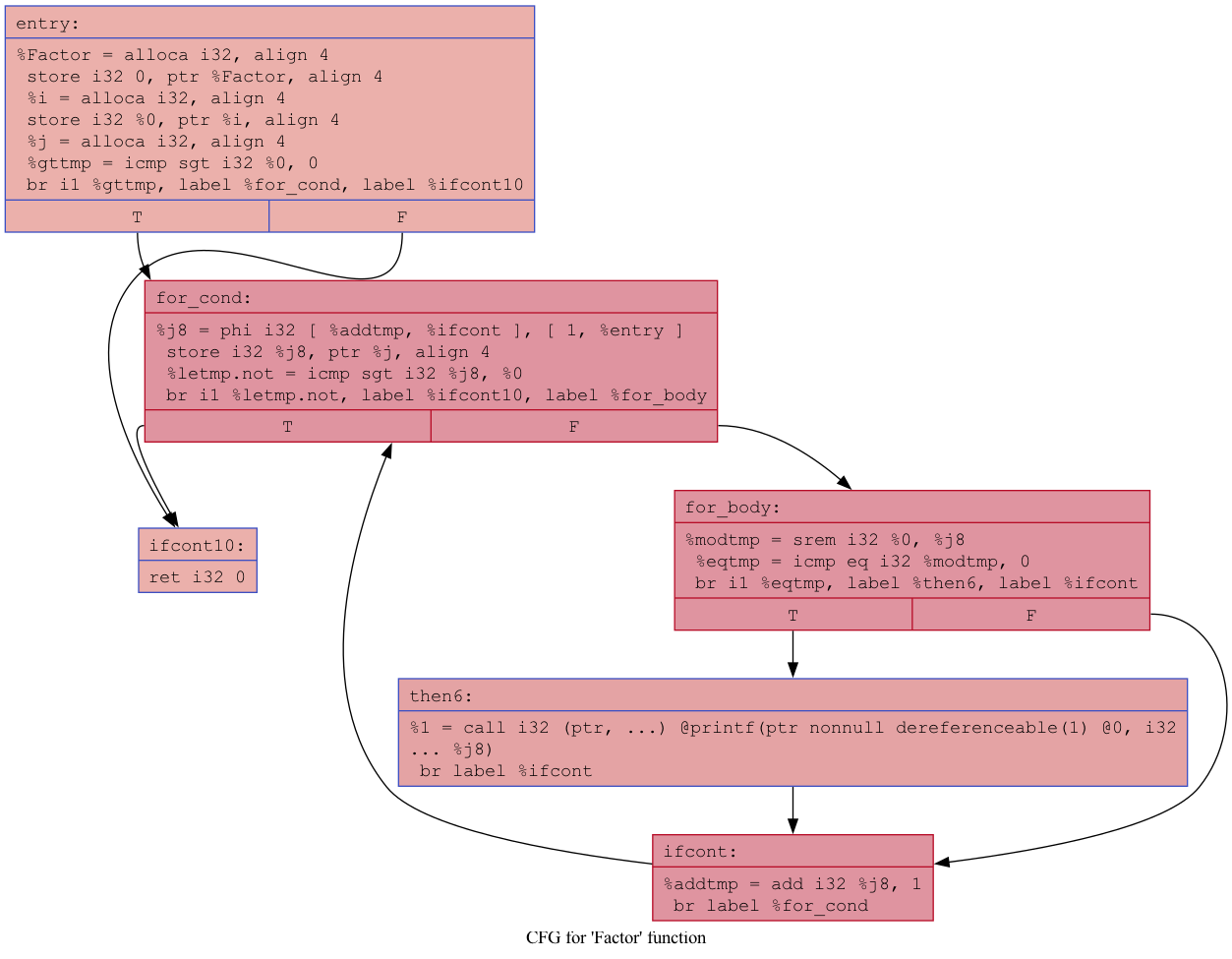
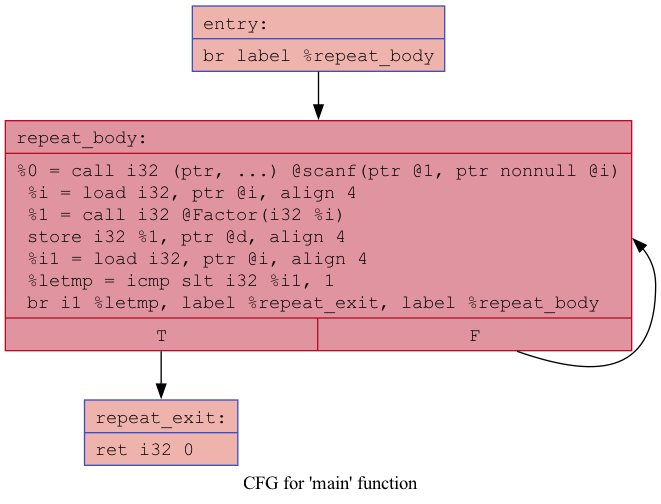
LLVM bitcode for the 'factors' program after optimizations
; ModuleID = 'factors'
source_filename = "factors"
@d = internal global i32 0
@i = internal global i32 0
@0 = private unnamed_addr constant [4 x i8] c"%d\0A\00", align 1
@1 = private unnamed_addr constant [3 x i8] c"%d\00", align 1
declare i32 @printf(i8*, ...)
declare i32 @scanf(i8*, ...)
define i32 @Factor(i32 %0) {
entry:
%Factor = alloca i32, align 4
store i32 0, i32* %Factor, align 4
%i = alloca i32, align 4
store i32 %0, i32* %i, align 4
%j = alloca i32, align 4
%gttmp = icmp sgt i32 %0, 0
br i1 %gttmp, label %for_cond, label %ifcont10
for_cond: ; preds = %entry, %ifcont
%j8 = phi i32 [ %addtmp, %ifcont ], [ 1, %entry ]
store i32 %j8, i32* %j, align 4
%letmp.not = icmp sgt i32 %j8, %0
br i1 %letmp.not, label %ifcont10, label %for_body
for_body: ; preds = %for_cond
%modtmp = srem i32 %0, %j8
%eqtmp = icmp eq i32 %modtmp, 0
br i1 %eqtmp, label %then6, label %ifcont
then6: ; preds = %for_body
%1 = call i32 (i8*, ...) @printf(i8* nonnull dereferenceable(1) getelementptr inbounds ([4 x i8], [4 x i8]* @0, i64 0, i64 0), i32 %j8)
br label %ifcont
ifcont: ; preds = %for_body, %then6
%addtmp = add i32 %j8, 1
br label %for_cond
ifcont10: ; preds = %entry, %for_cond
ret i32 0
}
define i32 @main() {
entry:
br label %repeat_body
repeat_body: ; preds = %repeat_body, %entry
%0 = call i32 (i8*, ...) @scanf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @1, i64 0, i64 0), i32* nonnull @i)
%i = load i32, i32* @i, align 4
%1 = call i32 @Factor(i32 %i)
store i32 %1, i32* @d, align 4
%i1 = load i32, i32* @i, align 4
%letmp = icmp slt i32 %i1, 1
br i1 %letmp, label %repeat_exit, label %repeat_body
repeat_exit: ; preds = %repeat_body
ret i32 0
}CFGs for the 'factors' program after optimizations
Decisions that simplified the code generation process
- There is an instruction in LLVM called a phi node. It is used to read values from registers and transfer them to another register in the next entering block (as the value is determined by the block from which the entry occurs). While it's true that programs are faster when utilizing registers rather than loading from memory, I've decided to use store and load instructions consistently everywhere and let the optimization stage determine the usage of phi nodes. This approach eliminates the need to address unwanted complexity upfront.
- I've also kept a common block labeled as the exit block at the end of each function. This block serves as the last block to be entered from any other block within the function, ensuring a structured flow of control.
- Additionally, I allocate a variable with the function name and the return type to handle the return value. Therefore, the actual ret statement is only present in the exit block. Whenever a 'return' statement is encountered in the WinZigC program, it is essentially transformed into a store operation to the return variable, with an added br (branch) instruction to the exit block. This approach ensures that 'assignments to the function name within the function' are handled solely by using store instructions.
Conclusion
This is a short post to share the story behind writing WinZigC compiler. I know I'm not a compiler expert, but this project provided me with valuable knowledge in that space. Not only that, but it was also a truly satisfying project for me. I hope you enjoyed it too. Feel free to explore the code and play with it. You can even try implementing the loop-pool control flow, which is a never-ending loop but can draw insights from other loop structures in the code. Hope to see you with a new post!
Happy Coding!
If you like it, share it!